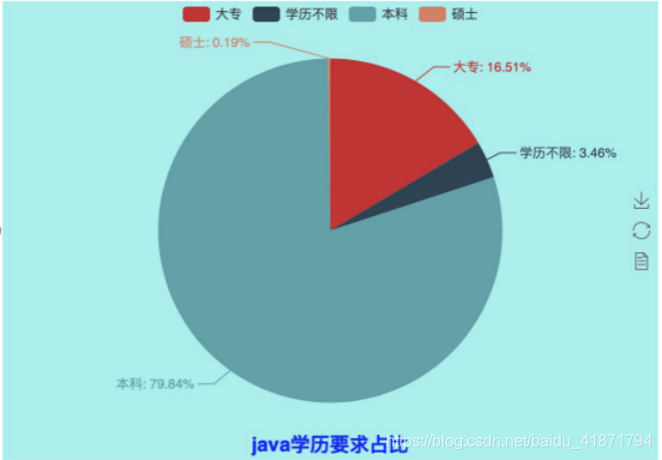
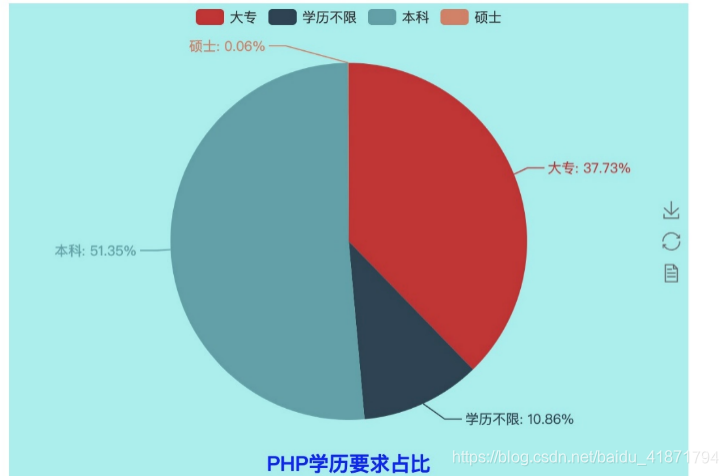
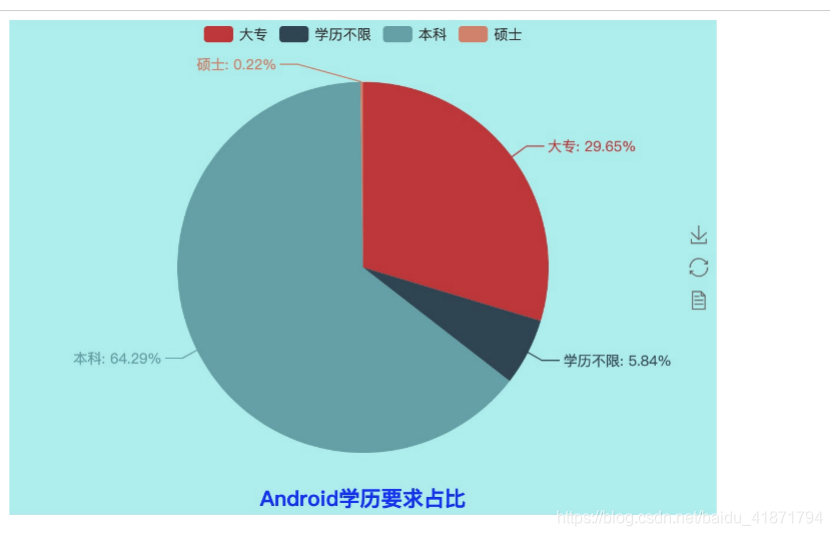
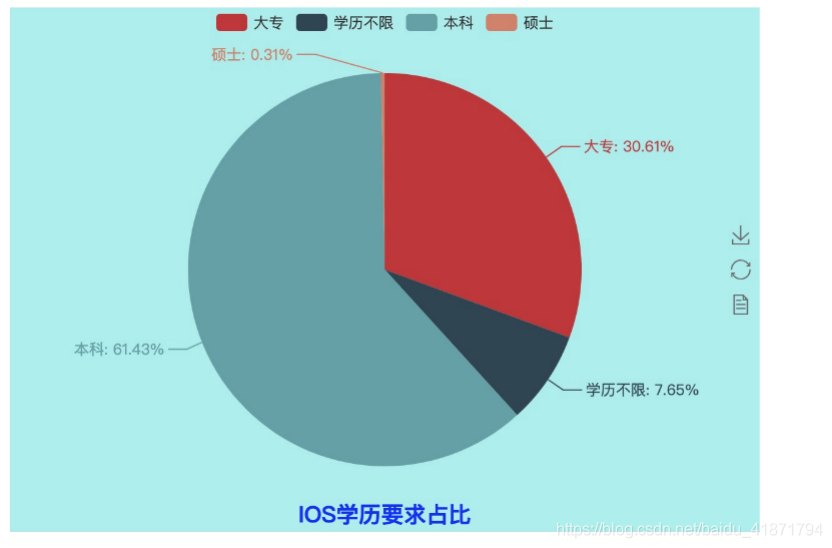
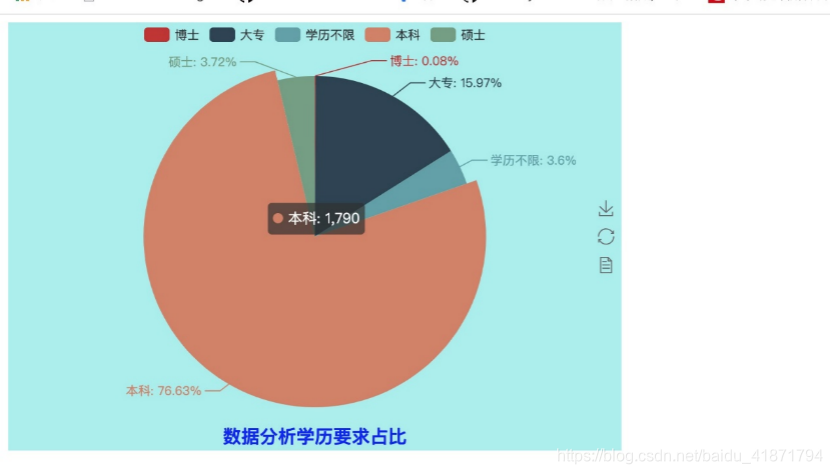
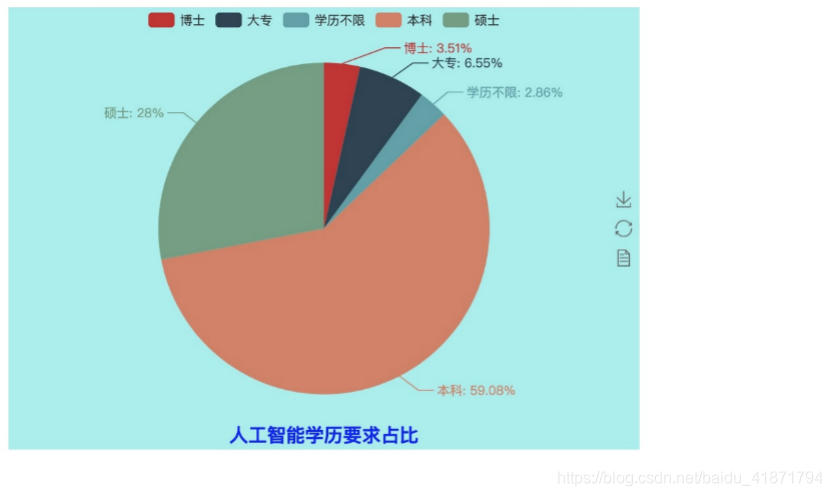
import random
import re
import pymysql
import requests
from bs4 import BeautifulSoup
cookie = '网页登陆后,复制cookie到这里'
conn = pymysql.connect(
host="xxxx",
user="xxx", password="xxx",
database="xxx",
charset="utf8")
cursor = conn.cursor()
base_url = "https://www.zhipin.com"
job_type = ["Java", "PHP", "web前端", "iOS", "Android", "算法工程师", "数据分析师", "数据架构师", "数据挖掘", "人工智能", " 机器学习", "深度学习"]
city_name = ["北京", "上海", "广州", "深圳", "杭州", "天津", "西安", "苏州", "武汉", "厦门", "长沙", "成都", "郑州", "重庆"]
city_num = ["c101010100", "c101020100", "c101280100", "c101280600", "c101210100", "c101030100", "c101110100",
"c101190400", "c101200100", "c101230200",
"c101250100", "c101270100", "c101180100", "c101040100"]
def get_user_agent():
user_list = [
"Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16",
"Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14",
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
"Opera/12.0(Windows NT 5.2;U;en)Presto/22.9.168 Version/12.00",
"Opera/12.0(Windows NT 5.1;U;en)Presto/22.9.168 Version/12.00",
"Mozilla/5.0 (Windows NT 5.1) Gecko/20100101 Firefox/14.0 Opera/12.0",
"Opera/9.80 (Windows NT 6.1; WOW64; U; pt) Presto/2.10.229 Version/11.62",
"Opera/9.80 (Windows NT 6.0; U; pl) Presto/2.10.229 Version/11.62",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; de) Presto/2.9.168 Version/11.52",
"Opera/9.80 (Windows NT 5.1; U; en) Presto/2.9.168 Version/11.51",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; de) Opera 11.51",
"Opera/9.80 (X11; Linux x86_64; U; fr) Presto/2.9.168 Version/11.50",
"Opera/9.80 (X11; Linux i686; U; hu) Presto/2.9.168 Version/11.50",
"Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11",
"Opera/9.80 (X11; Linux i686; U; es-ES) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/5.0 Opera 11.11",
"Opera/9.80 (X11; Linux x86_64; U; bg) Presto/2.8.131 Version/11.10",
"Opera/9.80 (Windows NT 6.0; U; en) Presto/2.8.99 Version/11.10",
"Opera/9.80 (Windows NT 5.1; U; zh-tw) Presto/2.8.131 Version/11.10",
"Opera/9.80 (Windows NT 6.1; Opera Tablet/15165; U; en) Presto/2.8.149 Version/11.1",
"Opera/9.80 (X11; Linux x86_64; U; Ubuntu/10.10 (maverick); pl) Presto/2.7.62 Version/11.01",
"Opera/9.80 (X11; Linux i686; U; ja) Presto/2.7.62 Version/11.01",
"Opera/9.80 (X11; Linux i686; U; fr) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 6.1; U; zh-tw) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 6.1; U; sv) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 6.1; U; en-US) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 6.1; U; cs) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 6.0; U; pl) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 5.2; U; ru) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 5.1; U;) Presto/2.7.62 Version/11.01",
"Opera/9.80 (Windows NT 5.1; U; cs) Presto/2.7.62 Version/11.01",
"Mozilla/5.0 (Windows NT 6.1; U; nl; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 Opera 11.01",
"Mozilla/5.0 (Windows NT 6.1; U; de; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 Opera 11.01",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; de) Opera 11.01",
"Opera/9.80 (X11; Linux x86_64; U; pl) Presto/2.7.62 Version/11.00",
"Opera/9.80 (X11; Linux i686; U; it) Presto/2.7.62 Version/11.00",
"Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.6.37 Version/11.00",
"Opera/9.80 (Windows NT 6.1; U; pl) Presto/2.7.62 Version/11.00",
"Opera/9.80 (Windows NT 6.1; U; ko) Presto/2.7.62 Version/11.00",
"Opera/9.80 (Windows NT 6.1; U; fi) Presto/2.7.62 Version/11.00",
"Opera/9.80 (Windows NT 6.1; U; en-GB) Presto/2.7.62 Version/11.00",
"Opera/9.80 (Windows NT 6.1 x64; U; en) Presto/2.7.62 Version/11.00",
"Opera/9.80 (Windows NT 6.0; U; en) Presto/2.7.39 Version/11.00"
]
user_agent = random.choice(user_list)
return user_agent
def get_page(url):
headers = {
'user-agent': "Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16",
'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
'accept-encoding': "gzip, deflate, br",
'accept-language': "zh-CN,zh;q=0.9,en;q=0.8",
'cookie': cookie,
'cache-control': "no-cache",
'referer': 'https://www.zhipin.com/?ka=header-home'
}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
return response.text
except requests.ConnectionError as e:
print('Error', e.args)
def translate(str):
line = str.strip()
pattern = re.compile('[^\u4e00-\u9fa50-9]')
zh = " ".join(pattern.split(line)).strip()
outStr = zh
return outStr
def get_job(url, conn, cursor, city_name_x):
html = get_page(url)
soup = BeautifulSoup(html, 'lxml')
job_all = soup.find_all('div', class_="job-primary")
if (job_all == []):
print("cookie已过期")
for job in job_all:
try:
job_title = job.find('span', class_="job-name").string
job_salary = job.find('span', class_="red").string
job_tag1 = job.p.text
job_company = job.find('div', class_="company-text").a.text
job_url = base_url + job.find('div', class_="company-text").a.attrs['href']
job_tag2 = job.find('div', class_="company-text").p.text
job_time = job.find('span', class_="job-pub-time").text
job_acquire = translate(str(job.find('p')))
print(job_title, job_salary, job_tag1, job_company, job_url, job_tag2, job_time, job_acquire, city_name_x)
store_data(job_title, job_salary, job_tag1, job_company, job_url, job_tag2, job_time, job_acquire,
city_name_x, conn, cursor, )
except Exception as e:
print(str(e))
def store_data(job_title1, job_salary1, job_lable1, job_company1, job_url1, job_company_tag1, job_time1, job_acquire1,
company_city1, conn, cursor):
try:
cursor.execute(
'insert into job_data (job_title,job_salary,job_lable,job_company,job_url,job_company_tag,job_time,job_acquire,company_city) '
'values ("{}","{}","{}","{}","{}","{}","{}","{}","{}")'.format(job_title1, job_salary1, job_lable1,
job_company1, job_url1,
job_company_tag1, job_time1,
job_acquire1, company_city1))
except:
print("存入数据库失败")
conn.commit()
city_no = 5
page = str(1)
key = job_type[11]
url = base_url + "/" + "c101190100" + "/?" + "query=" + key + "&page=" + page + "&ka=page-" + page
print(url)
get_job(url=url, conn=conn, cursor=cursor, city_name_x="南京")
cursor.close()
conn.close()
|