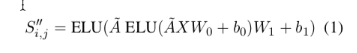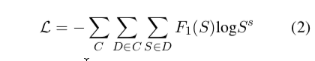多文档摘要论文复现
- 1.数据集说明
数据集需要在https://www-nlpir.nist.gov/projects/duc/guidelines.html进行申请
- 2.读取数据
- 3.切分句子
- 4.将切分完的句子建立索引
- 5.代码实现
import osimport reimport utilclass LoadData (object def __init__ (self ): self.data_set = {} self.data_set_summary = {} self.current_path = os.path.abspath(os.path.dirname(__file__)) self.train_set = {} self.validation_set = {} self.test_set = {} self.train_set_len = 0 self.validation_set_len = 0 self.test_set_len = 0 self.train_set_sentences = {} self.validation_set_sentences = {} self.test_set_sentences = {} self.index_to_sentence = {} self.sentence_to_index = {} self.train_set_sencence_count = 0 self.train_set_sentences_list = {} self.train_index = [] self.validation_set_sencence_count = 0 self.validation_set_sentences_list = {} self.validation_index = [] self.test_set_sencence_count = 0 self.test_set_sentences_list = {} self.test_index = [] self.train_set_summary = {} self.validation_set_summary = {} self.test_set_summary = {} def read_data (self ): DUC2001_path = self.current_path + '/data/DUC/DUC2001_Summarization_Documents/data/training' DUC2001_files = os.listdir(DUC2001_path) for file in DUC2001_files: if os.path.isdir(DUC2001_path + "/" + file): doc_path_list = DUC2001_path + "/" + file + "/docs" summary_path = DUC2001_path + "/" + file + "/" + file + str (file)[-1 ] for doc_path in os.listdir(doc_path_list): if os.path.isfile(doc_path_list + "/" + doc_path): self.get_data(doc_path_list + "/" + doc_path, summary_path + "/perdocs" ) DUC2001_path_test = self.current_path + '/data/DUC/DUC2001_Summarization_Documents/data/test' DUC2001_files_test = os.listdir(DUC2001_path_test + "/docs" ) for file in DUC2001_files_test: if os.path.isdir(DUC2001_path_test + "/docs/" + file): doc_path_list = DUC2001_path_test + "/docs/" + file summary_path = DUC2001_path_test + "/original.summaries/" + file + str (file)[-1 ] for doc_path in os.listdir(doc_path_list): if os.path.isfile(doc_path_list + "/" + doc_path): self.get_data(doc_path_list + "/" + doc_path, summary_path + "/perdocs" ) DUC2001_path_testtraining = self.current_path + '/data/DUC/DUC2001_Summarization_Documents/data/testtraining/duc2002testtraining' DUC2001_files_testtraining = os.listdir(DUC2001_path_testtraining) for file in DUC2001_files_testtraining: if os.path.isdir(DUC2001_path_testtraining + "/" + file): path_list = os.listdir(DUC2001_path_testtraining + "/" + file) for path in path_list: doc_no = path fr_doc = open (DUC2001_path_testtraining + "/" + file + "/" + path + "/" + path + ".body" , encoding='utf-8' ) content = fr_doc.read() content = content.replace("\n" , "" ) self.data_set[doc_no] = content fr_summary = open (DUC2001_path_testtraining + "/" + file + "/" + path + "/" + path + ".abs" , encoding='utf-8' ) summary = fr_summary.read() summary = summary.replace("\n" , "" ) self.data_set_summary[doc_no] = summary length = len (self.data_set) self.train_set_len = int (length * 0.8 ) self.validation_set_len = int (length * 0.1 ) self.test_set_len = int (length * 0.1 ) index = 0 for doc_no,content in self.data_set.items(): if index < self.train_set_len: self.train_set[doc_no] = content self.train_set_summary[doc_no] = self.data_set_summary[doc_no] elif index > self.train_set_len and index<self.train_set_len+self.validation_set_len: self.validation_set[doc_no] = content self.validation_set_summary[doc_no] = self.data_set_summary[doc_no] elif index > self.train_set_len+self.validation_set_len and index < length: self.test_set[doc_no] = content self.test_set_summary[doc_no] = self.data_set_summary[doc_no] index +=1 """利用正则表达式,提取文档内容和文档的摘要""" def get_data (self, doc_path, summary_path ): fr = open (doc_path, "r" , encoding='utf-8' ) content = fr.read() content = content.replace("\n" , "" ) doc = re.findall("<TEXT>(.*?)</TEXT>" , content)[0 ] doc_no = re.findall("<DOCNO>(.*?)</DOCNO>" , content)[0 ].replace(" " , "" ) self.data_set[doc_no] = doc.replace("<p>" , "" ).replace("</p>" , "" ).replace("<P>" , "" ).replace( "</P>" , "" ) fr = open (summary_path, "r" , encoding='utf-8' ) summary_list = fr.read() summary_list = summary_list.replace("\n" , "" ) summary = re.findall('<SUM.*?DOCREF="{}.*?">(.*?)</SUM>' .format (doc_no), summary_list)[0 ] self.data_set_summary[doc_no] = summary """将文档切分成句子""" def cut_doc_to_sentences (self, set ="train_set" ): sentences_count = 0 j = 0 if set == "train_set" : for doc_no, doc_content in self.train_set.items(): sentence_list = util.cut_doc_to_sentences(doc_content) if (len (sentence_list)) == 0 : break document_dict = {} sentences_count += len (sentence_list) for i in range (len (sentence_list)): document_dict["sen_id_" + str (i)] = sentence_list[i] self.train_set_sentences[doc_no] = document_dict self.train_set_sencence_count = sentences_count elif set == "validation_set" : for doc_no, doc_content in self.validation_set.items(): sentence_list = util.cut_doc_to_sentences(doc_content) if (len (sentence_list)) == 0 : break document_dict = {} sentences_count += len (sentence_list) for i in range (len (sentence_list)): document_dict["sen_id_" + str (i)] = sentence_list[i] self.validation_set_sentences[doc_no] = document_dict self.validation_set_sencence_count = sentences_count elif set == "test_set" : for doc_no, doc_content in self.test_set.items(): sentence_list = util.cut_doc_to_sentences(doc_content) if (len (sentence_list)) == 0 : break document_dict = {} sentences_count += len (sentence_list) for i in range (len (sentence_list)): document_dict["sen_id_" + str (i)] = sentence_list[i] self.test_set_sentences[doc_no] = document_dict self.test_set_sencence_count = sentences_count def create_index (self ): index = 0 for doc_no, sentences in self.train_set_sentences.items(): sentence_index_list = [] for sen_id, sentence in sentences.items(): self.index_to_sentence[index] = doc_no + "#" + sen_id self.sentence_to_index[doc_no + "#" + sen_id] = index sentence_index_list.append(index) self.train_index.append(index) index += 1 self.train_set_sentences_list[doc_no] = sentence_index_list for doc_no, sentences in self.validation_set_sentences.items(): sentence_index_list = [] for sen_id, sentence in sentences.items(): self.index_to_sentence[index] = doc_no + "#" + sen_id self.sentence_to_index[doc_no + "#" + sen_id] = index sentence_index_list.append(index) self.validation_index.append(index) index += 1 self.validation_set_sentences_list[doc_no] = sentence_index_list for doc_no, sentences in self.test_set_sentences.items(): sentence_index_list = [] for sen_id, sentence in sentences.items(): self.index_to_sentence[index] = doc_no + "#" + sen_id self.sentence_to_index[doc_no + "#" + sen_id] = index sentence_index_list.append(index) self.test_index.append(index) index += 1 self.test_set_sentences_list[doc_no] = sentence_index_list def read (self ): self.read_data() self.cut_doc_to_sentences(set ="train_set" ) self.cut_doc_to_sentences(set ="validation_set" ) self.cut_doc_to_sentences(set ="test_set" ) self.create_index()
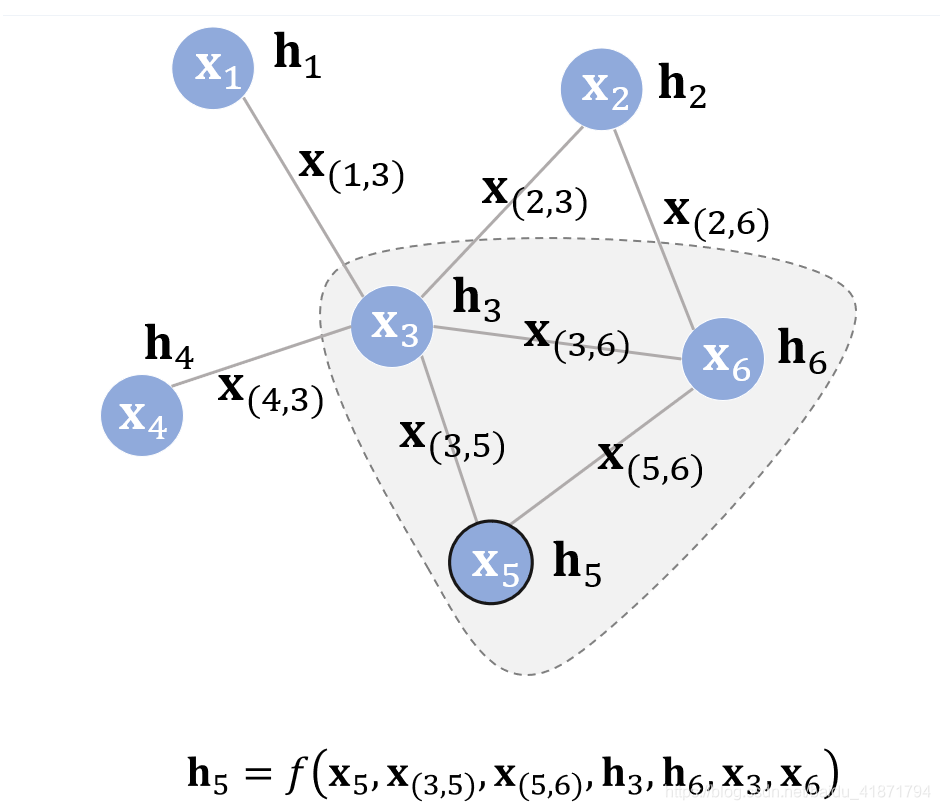
(1)用图对句子建模,图的顶点为文档i中的句子j(Si,j),边为两个句子之间的相似程度。需要使用英语Wikipedia语料库上训练的的模型进行句子嵌入(sentence embeddings),产生句子的向量,然后根据向量计算句子之间的余弦相似度,然后构建矩阵。
2.sentence embeddings环境安装工作
我找到了(Pagliardini et al. (2018))的论文中描述的模型的开源实现,他可以在fasttext库的基础上,进行句子嵌入。
sent2vec模型地址:https://github.com/epfml/sent2vec
(1)由于他基于fasttext,所以先下载并编译了fasttext,具体方法他在github中写的非常清楚,在他们目录文件中写好了Makefile,直接用本地的gcc环境进行编译
https://github.com/facebookresearch/fastText
(2)下载论文中描述的的wiki百科600维的预训练unigram模型,在fasttext中进行使用
https://drive.google.com/uc?id=0B6VhzidiLvjSa19uYWlLUEkzX3c&export=download
(3)下载了斯坦福解析器,配合nltk库进行Tokenizer
解析器下载:https://nlp.stanford.edu/software/lex-parser.shtml#Download https://blog.csdn.net/qq_36652619/article/details/75091327
3.使用nltk库和斯坦福解析器,进行Tokenizer,然后使用wiki百科600维的预训练unigram模型进行sentence embeddings
import osimport timeimport refrom subprocess import callimport numpy as npfrom nltk.tokenize.stanford import StanfordTokenizerclass SentencesEmbeddings (object def __init__ (self ): self.FASTTEXT_EXEC_PATH = os.path.abspath("./sent2vec-master/fasttext" ) self.BASE_SNLP_PATH = "sent2vec-master/stanford-postagger-full/" self.SNLP_TAGGER_JAR = os.path.join(self.BASE_SNLP_PATH, "stanford-postagger.jar" ) self.MODEL_WIKI_UNIGRAMS = os.path.abspath("sent2vec-master/wiki_unigrams.bin" ) self.tknzr = StanfordTokenizer(self.SNLP_TAGGER_JAR, encoding='utf-8' ) print("SentencesEmbeddings初始化完成" ) def tokenize (self, sentence, to_lower=True ): """Arguments: - tknzr: a tokenizer implementing the NLTK tokenizer interface - sentence: a string to be tokenized - to_lower: lowercasing or not """ sentence = sentence.strip() sentence = ' ' .join([self.format_token(x) for x in self.tknzr.tokenize(sentence)]) if to_lower: sentence = sentence.lower() sentence = re.sub('((www\.[^\s]+)|(https?://[^\s]+)|(http?://[^\s]+))' ,'<url>' ,sentence) sentence = re.sub('(\@[^\s]+)' ,'<user>' ,sentence) filter (lambda word: ' ' not in word, sentence) return sentence def format_token (self,token ): """""" if token == '-LRB-' : token = '(' elif token == '-RRB-' : token = ')' elif token == '-RSB-' : token = ']' elif token == '-LSB-' : token = '[' elif token == '-LCB-' : token = '{' elif token == '-RCB-' : token = '}' return token def tokenize_sentences (self, sentences, to_lower=True ): """Arguments: - tknzr: 斯坦福解析器 - sentences:句子列表 - to_lower: 是否转化成消协 """ return [self.tokenize( s, to_lower) for s in sentences] def get_embeddings_for_preprocessed_sentences (self,sentences, model_path, fasttext_exec_path ): """Arguments: - sentences:分词后的结果 - model_path: wiki百科模型文件的路径 - fasttext_exec_path: fasttext的路径 """ timestamp = str (time.time()) test_path = os.path.abspath('./' +timestamp+'_fasttext.test.txt' ) embeddings_path = os.path.abspath('./' +timestamp+'_fasttext.embeddings.txt' ) self.dump_text_to_disk(test_path, sentences) call(fasttext_exec_path+ ' print-sentence-vectors ' + model_path + ' < ' + test_path + ' > ' + embeddings_path, shell=True ) embeddings = self.read_embeddings(embeddings_path) os.remove(test_path) os.remove(embeddings_path) assert (len (sentences) == len (embeddings)) return np.array(embeddings) def read_embeddings (self,embeddings_path ): """Arguments: - embeddings_path: path to the embeddings """ with open (embeddings_path, 'r' ) as in_stream: embeddings = [] for line in in_stream: line = '[' +line.replace(' ' ,',' )+']' embeddings.append(eval (line)) return embeddings return [] def dump_text_to_disk (self,file_path, X, Y=None ): """Arguments: - file_path: where to dump the data - X: list of sentences to dump - Y: labels, if any """ with open (file_path, 'w' ) as out_stream: if Y is not None : for x, y in zip (X, Y): out_stream.write('__label__' +str (y)+' ' +x+' \n' ) else : for x in X: out_stream.write(x+' \n' ) def get_sentence_embeddings (self,sentences ): wiki_embeddings = None s = ' <delimiter> ' .join(sentences) tokenized_sentences_SNLP = self.tokenize_sentences([s]) tokenized_sentences_SNLP = tokenized_sentences_SNLP[0 ].split(' <delimiter> ' ) assert (len (tokenized_sentences_SNLP) == len (sentences)) wiki_embeddings = self.get_embeddings_for_preprocessed_sentences(tokenized_sentences_SNLP, \ self.MODEL_WIKI_UNIGRAMS, self.FASTTEXT_EXEC_PATH) return wiki_embeddings def embeddings (self,sentences ): my_embeddings = self.get_sentence_embeddings(sentences) return my_embeddings
""" 构造语义关系图 以及进行sentence encoder """ import SentencesEmbeddingsimport numpy as npimport reimport utilclass SentenceSemanticRelationGraph (object def __init__ (self, train_set_sentences, validation_set_sentences, test_set_sentences, train_set_sencence_count, validation_set_sencence_count, test_set_sencence_count, sentence_to_index, index_to_sentence, train_set_sentences_list, validation_set_sentences_list, test_set_sentences_list, train_index, validation_index, test_index ): self.sentences_embeddings = SentencesEmbeddings.SentencesEmbeddings() self.train_set_sentences = train_set_sentences self.validation_set_sentences = validation_set_sentences self.test_set_sentences = test_set_sentences self.train_set_sencence_count = train_set_sencence_count self.validation_set_sencence_count = validation_set_sencence_count self.test_set_sencence_count = test_set_sencence_count self.sentence_count = train_set_sencence_count+validation_set_sencence_count+test_set_sencence_count self.data_set_sentences_embeddings = {} self.data_set_sentences = {} self.tgsim = 0.35 self.index_to_sentence = index_to_sentence self.sentence_to_index = sentence_to_index self.data_set_cosine_similarity_matrix = None self.data_set_sentences_list = {} self.train_index = train_index self.train_set_sentences_list = train_set_sentences_list self.validation_index = validation_index self.validation_set_sentences_list = validation_set_sentences_list self.test_index = test_index self.test_set_sentences_list = test_set_sentences_list """ 处理已经读入的训练集 测试集 验证集 """ def deal_data (self ): for doc_no, sentences_list in self.train_set_sentences_list.items(): self.data_set_sentences_list[doc_no] = sentences_list for doc_no, sentences_list in self.validation_set_sentences_list.items(): self.data_set_sentences_list[doc_no] = sentences_list for doc_no, sentences_list in self.test_set_sentences_list.items(): self.data_set_sentences_list[doc_no] = sentences_list for doc_no, sentences_list in self.train_set_sentences.items(): self.data_set_sentences[doc_no] = sentences_list for doc_no, sentences_list in self.validation_set_sentences.items(): self.data_set_sentences[doc_no] = sentences_list for doc_no, sentences_list in self.test_set_sentences.items(): self.data_set_sentences[doc_no] = sentences_list """ 调用方法计算句子嵌入 """ def calculate_sentences_embeddings (self ): for doc_no, sentence_index_list in self.data_set_sentences_list.items(): index_list = [] sentence_list = [] for index in sentence_index_list: sen_id = str (self.index_to_sentence[index]).split("#" )[1 ] sentence = self.data_set_sentences[doc_no][sen_id] sentence_list.append(sentence) index_list.append(index) sentence_embedding_list = self.sentences_embeddings.embeddings(sentence_list) for i in range (len (index_list)): self.data_set_sentences_embeddings[index_list[i]] = sentence_embedding_list[i] """ 计算句子间的余弦相似度 构造语义关系图 """ def calculate_cosine_similarity_matrix (self ): self.data_set_cosine_similarity_matrix = np.zeros( (self.sentence_count, self.sentence_count)) for index, id in self.index_to_sentence.items(): for index2, id2 in self.index_to_sentence.items(): if index == index2 : break if self.data_set_cosine_similarity_matrix[index][index2] == 0 : embeddings1 = self.data_set_sentences_embeddings[index] embeddings2 = self.data_set_sentences_embeddings[index2] cosine_similarity = self.calculate_cosine_similarity(embeddings1, embeddings2) if cosine_similarity > self.tgsim: self.data_set_cosine_similarity_matrix[index][index2] = cosine_similarity self.data_set_cosine_similarity_matrix[index2][index] = cosine_similarity else : continue """ 计算两个numpy向量之间的余弦相似度 """ def calculate_cosine_similarity (self,vector1,vector2 ): cosine_similarity = np.dot(vector1,vector2)/(np.linalg.norm(vector1)*(np.linalg.norm(vector2))) return cosine_similarity
解释:
获得读取到的数据,将其构成几个集合:
然后调用方法计算每一篇文档的sentence embeddings,存储格式为{reviewer_id1:{sen_id1:embeddings1,sen_id2:embeddings2} ,reviewer_id2:{sen_id1:embeddings1,sen_id2:embeddings2} }。
最后借助sentence embeddings,来计算句子语义关系图data_set_cosine_similarity_matrix
至此,第一部分的工作完成。
- 1.解释
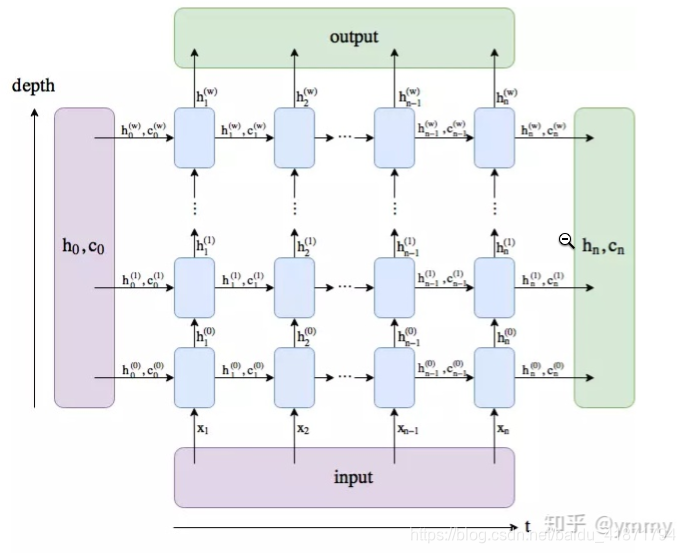
- 2.循环神经网络RNN的学习
https://zhuanlan.zhihu.com/p/50915723 https://zhuanlan.zhihu.com/p/30844905
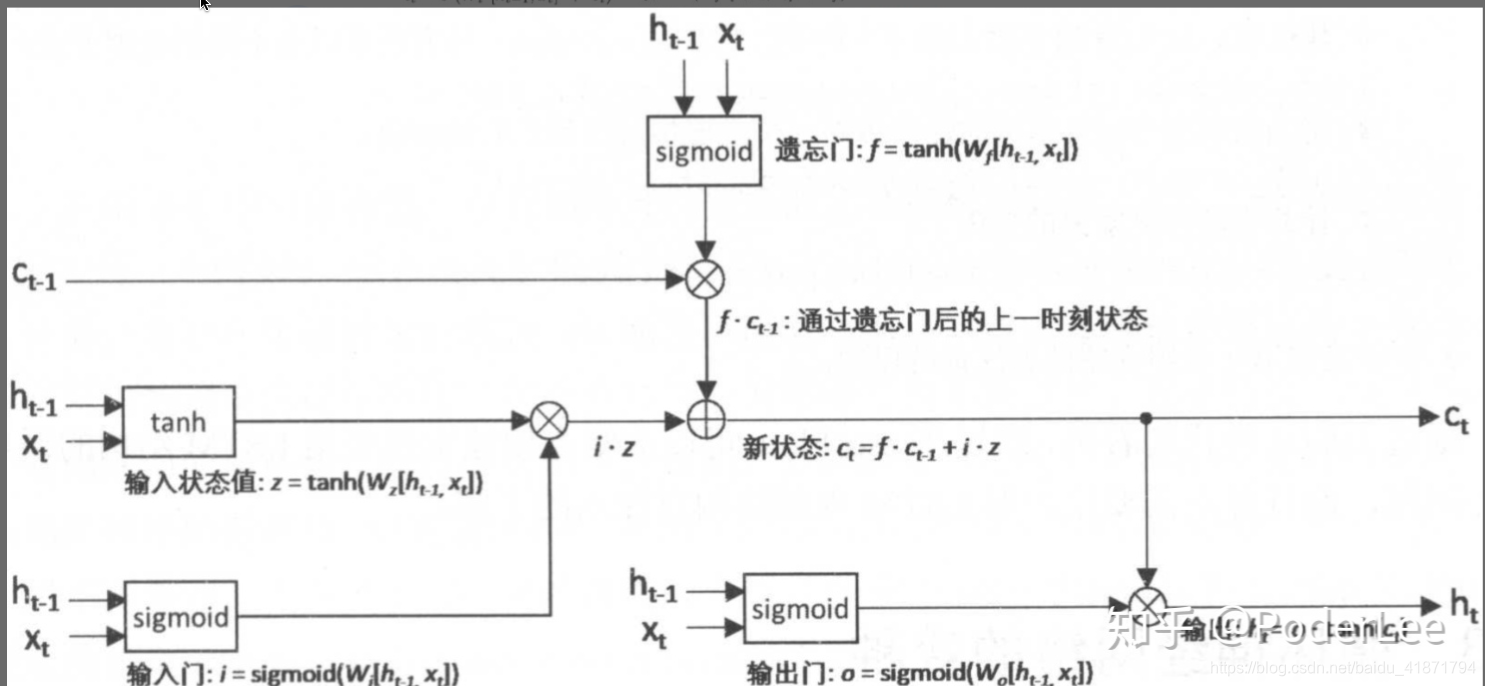
- 3.LSTM:
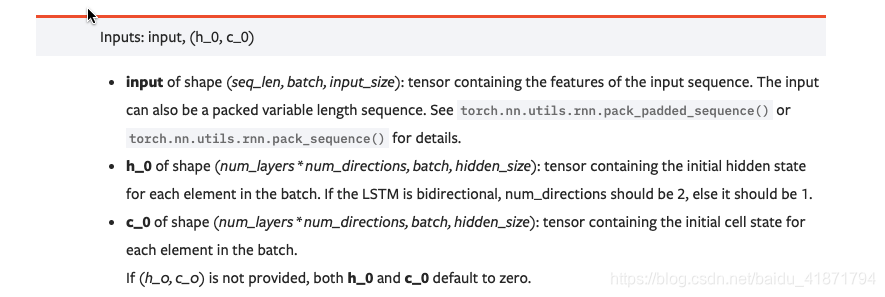
https://pytorch.org/docs/master/generated/torch.nn.LSTM.html https://zhuanlan.zhihu.com/p/79064602
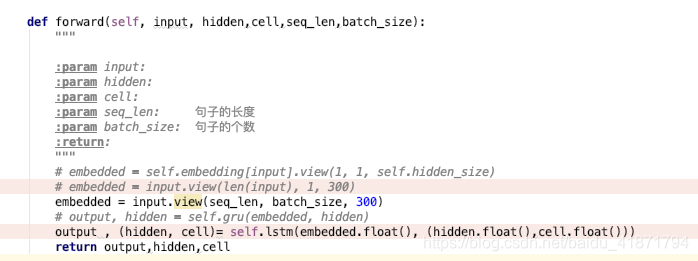
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) class EncoderRNN (nn.Module ): def __init__ (self, input_size, hidden_size,batch_size ): super (EncoderRNN, self).__init__() self.hidden_size = hidden_size self.input_size = input_size self.batch_size = batch_size self.lstm = nn.LSTM(self.input_size, hidden_size) def forward (self, input , hidden,cell,seq_len,batch_size ): """ :param input: :param hidden: :param cell: :param seq_len: 句子的长度 :param batch_size: 句子的个数 :return: """ embedded = input .view(seq_len, batch_size, 300 ) output , (hidden, cell)= self.lstm(embedded.float (), (hidden.float (),cell.float ())) return output,hidden,cell
(1)torch.nn.LSTM(*args, kwargs)
– dropout: 默认值0。是否在除最后一个 RNN 层外的其他 RNN 层后面加 dropout 层。输入值是 0-1 之间的小数,表示概率。0表示0概率dripout,即不dropout
4.word embeddings(使用预训练的glove进行词嵌入)
(1)下载预训练的模型
https://nlp.stanford.edu/projects/glove/
(2)glove模型的使用
from gensim.scripts.glove2word2vec import glove2word2vecglove_input_file = 'data/glove.6B.300d.txt' word2vec_output_file = 'data/glove.6B.300d.word2vec.txt' glove2word2vec(self.glove_input_file, self.word2vec_output_file)
转换过模型格式后,就可以使用里面的词向量了:
from gensim.models import KeyedVectorsglove_model = KeyedVectors.load_word2vec_format(word2vec_output_file, binary=False ) cat_vec = glove_model['cat' ] print(cat_vec)
import torchimport torch.nn as nnfrom torch import optimimport torch.nn.functional as Fimport refrom gensim.scripts.glove2word2vec import glove2word2vecfrom gensim.models import KeyedVectorsimport numpy as npimport jsonimport utildevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) class EncoderRNN (nn.Module ): def __init__ (self, input_size, hidden_size,batch_size ): super (EncoderRNN, self).__init__() self.hidden_size = hidden_size self.input_size = input_size self.batch_size = batch_size self.lstm = nn.LSTM(self.input_size, hidden_size) def forward (self, input , hidden,cell,seq_len,batch_size ): """ :param input: :param hidden: :param cell: :param seq_len: 句子的长度 :param batch_size: 句子的个数 :return: """ embedded = input .view(seq_len, batch_size, 300 ) output , (hidden, cell)= self.lstm(embedded.float (), (hidden.float (),cell.float ())) return output,hidden,cell def initHidden (self ): return torch.zeros(1 , self.batch_size, self.hidden_size, device=device,dtype=torch.float ) class SentenceEncoder (object def __init__ (self,data_set_sentences, sentence_to_index, index_to_sentence ) self.data_set_sentences = data_set_sentences #数据集 将文档切分成了句子 存储格式为 {doc_no :{sen_id:句子1 ,sen_id2 :句子2 }} self.data_set_word = {} self.sentence_to_index = sentence_to_index self.index_to_sentence = index_to_sentence self.data_set_sentence_word = {} self.data_set_sentence_count = 0 self.max_sentence_length = 0 self.data_set_sentence_word_to_vec = {} self.data_set_word_to_index = {} self.data_set_word_count = {} self.index_to_data_set_word = {} self.word_to_vec = {} self.number_word = 0 self.embeddings_size = 300 self.data_set_sentence_word_encoder = None self.glove_input_file = 'data/glove.6B.300d.txt' self.word2vec_output_file = 'data/glove.6B.300d.word2vec.txt' self.glove_model = KeyedVectors.load_word2vec_format(self.word2vec_output_file, binary=False ) def deal_data (self ): for index, sentence in self.index_to_sentence.items(): doc_no = str (sentence).split("#" )[0 ] sen_id = str (sentence).split("#" )[1 ] sentence = self.data_set_sentences[doc_no][sen_id] word_list = self.sentence_to_word(sentence) self.data_set_sentence_word[index] = word_list self.data_set_sentence_count += 1 def sentence_to_word (self, sentence ): sentence = util.normalize_string(sentence) word_list= [] for word in sentence.split(' ' ): word = util.normalize_string(word) if word != "" : self.addWord(word) word_list.append(word) if len (word_list) >self.max_sentence_length: self.max_sentence_length = len (word_list) return word_list def addWord (self, word ): if word not in self.data_set_word_to_index: self.data_set_word_to_index[word] = self.number_word self.data_set_word_count[word] = 1 self.index_to_data_set_word[self.number_word] = word self.number_word += 1 else : self.data_set_word_count[word] += 1 def glove_to_word2vec (self ): glove2word2vec(self.glove_input_file, self.word2vec_output_file) """ 获得词向量 """ def get_word_vec (self,word ): return self.glove_model[word] def word_to_vector (self ): for index , word in self.index_to_data_set_word.items(): try : word_vec = self.get_word_vec(word) except KeyError: word_vec = np.zeros(300 ) self.word_to_vec[word] = word_vec """ 将句子使用rnn进行encoder """ def sentence_encoder (self ): hedden_size = 300 encoder = EncoderRNN(300 , hedden_size,self.data_set_sentence_count).to(device) hidden = encoder.initHidden() cell = encoder.initHidden() output = None sentences_vector_list = [] for index ,words in self.data_set_sentence_word.items(): sentence_vector_list = [] count = 0 for word in words: sentence_vector_list.append(self.word_to_vec[word]) count +=1 sentence_vector_list = np.array(sentence_vector_list) sentence_vector_list = np.pad(sentence_vector_list,((0 ,self.max_sentence_length-count),(0 ,0 )),'constant' ,constant_values = (0 ,0 )) sentences_vector_list.append(sentence_vector_list) output,hidden, cell = encoder(self.sentence_to_tensor(sentences_vector_list), hidden, cell,self.max_sentence_length,self.data_set_sentence_count) print(hidden.shape) print(output.shape) self.data_set_sentence_word_encoder = output[output.shape[0 ]-1 ].tolist() """ 将句子向量转化成tensor """ def sentence_to_tensor (self, vector_list ): vector_array = np.array(vector_list) tensor = torch.tensor(vector_array, dtype=torch.float , device=device).view(self.data_set_sentence_count,self.max_sentence_length,300 ) return tensor
说明:
(2)对数据进行处理
self.train_set_word_to_index = {} self.train_set_word_count = {} self.index_to_train_set_word = {}
将训练集中所有出现过的单词进行统计,建立单个词语的索引。
def deal_data (self ): for index, sentence in self.index_to_sentence.items(): doc_no = str (sentence).split("#" )[0 ] sen_id = str (sentence).split("#" )[1 ] sentence = self.data_set_sentences[doc_no][sen_id] word_list = self.sentence_to_word(sentence) self.data_set_sentence_word[index] = word_list self.data_set_sentence_count += 1 def sentence_to_word (self, sentence ): sentence = util.normalize_string(sentence) word_list= [] for word in sentence.split(' ' ): word = util.normalize_string(word) if word != "" : self.addWord(word) word_list.append(word) if len (word_list) >self.max_sentence_length: self.max_sentence_length = len (word_list) return word_list def addWord (self, word ): if word not in self.data_set_word_to_index: self.data_set_word_to_index[word] = self.number_word self.data_set_word_count[word] = 1 self.index_to_data_set_word[self.number_word] = word self.number_word += 1 else : self.data_set_word_count[word] += 1
(3) 将句子使用LSTM进行encoder
使用之前处理过的句子的单词列表,求出每一句话中每一个单词的word embedding (1300),然后将这句话中的所有单词的word embedding ,组成一个 (句子中单词个数 300)维的矩阵。然后将这个矩阵的行数,补全成了最长句子的单词个数,最终形成的矩阵是 (最长句子的单词个数*300)。
我将所有句子都这样操作,形成了一个三维的张量 (句子个数 * 最长句子的单词个数*300)作为LSTM的输入。
那么在初始化LSTM时 为nn.LSTM(每个单词向量的长度——300, hidden_size)
然后我将hidden 和cell初始化成了 torch.zeros(1, 句子的个数, hidden_size)
对于input(seq_len, batch, input_size) 的参数 :
seq_len是序列的个数,对于句子来说,应该是句子的长度,应该是每一句话中单词的个数,这个是需要固定的 ,取了最长的句子的单词数。
batch表示一次性喂给网络多少条句子,初始化成句子的个数
input_size应该是每个具体的输入是多少维的向量,这里应该是300(word embedding的维度数量)
最终的hidden_size =300 最终生成了(句子的个数*300)的矩阵,作为Encoder的输出。
def glove_to_word2vec (self ): glove2word2vec(self.glove_input_file, self.word2vec_output_file) """ 获得词向量 """ def get_word_vec (self,word ): return self.glove_model[word] def word_to_vector (self ): for index , word in self.index_to_data_set_word.items(): try : word_vec = self.get_word_vec(word) except KeyError: word_vec = np.zeros(300 ) self.word_to_vec[word] = word_vec """ 将句子使用rnn进行encoder """ def sentence_encoder (self ): hedden_size = 300 encoder = EncoderRNN(300 , hedden_size,self.data_set_sentence_count).to(device) hidden = encoder.initHidden() cell = encoder.initHidden() output = None sentences_vector_list = [] for index ,words in self.data_set_sentence_word.items(): sentence_vector_list = [] count = 0 for word in words: sentence_vector_list.append(self.word_to_vec[word]) count +=1 sentence_vector_list = np.array(sentence_vector_list) sentence_vector_list = np.pad(sentence_vector_list,((0 ,self.max_sentence_length-count),(0 ,0 )),'constant' ,constant_values = (0 ,0 )) sentences_vector_list.append(sentence_vector_list) output,hidden, cell = encoder(self.sentence_to_tensor(sentences_vector_list), hidden, cell,self.max_sentence_length,self.data_set_sentence_count) print(hidden.shape) print(output.shape) self.data_set_sentence_word_encoder = output[output.shape[0 ]-1 ].tolist() """ 将句子向量转化成tensor """ def sentence_to_tensor (self, vector_list ): vector_array = np.array(vector_list) tensor = torch.tensor(vector_array, dtype=torch.float , device=device).view(self.data_set_sentence_count,self.max_sentence_length,300 ) return tensor
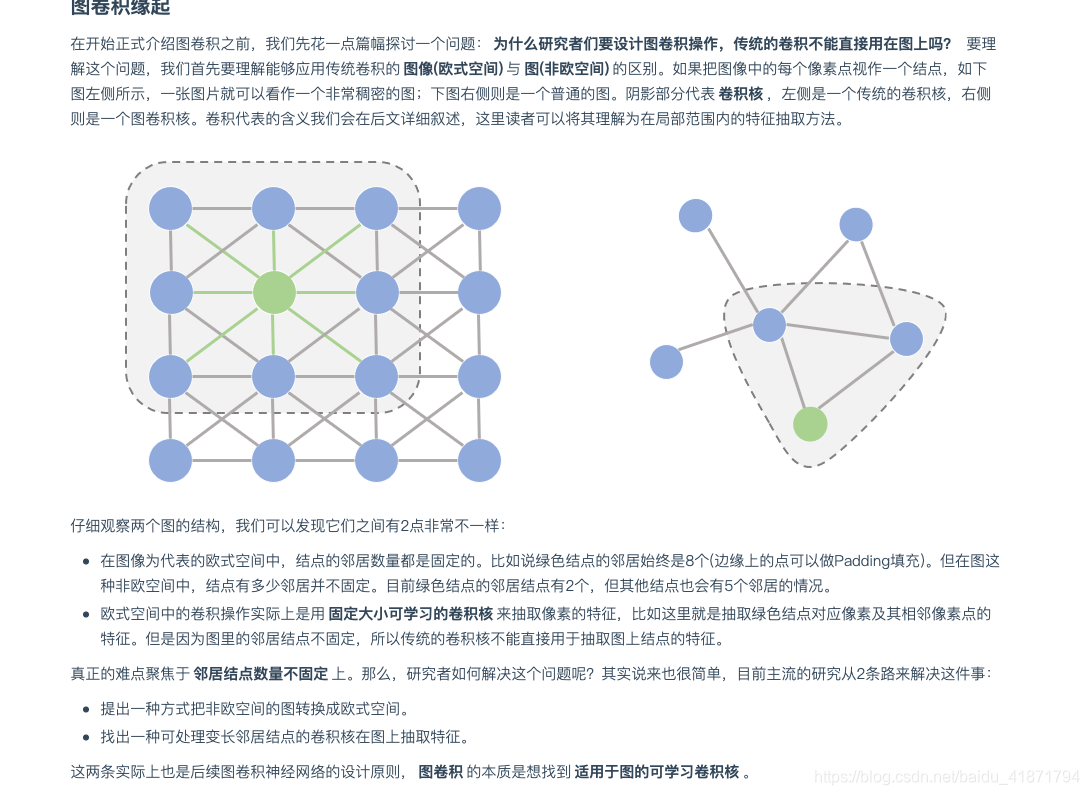
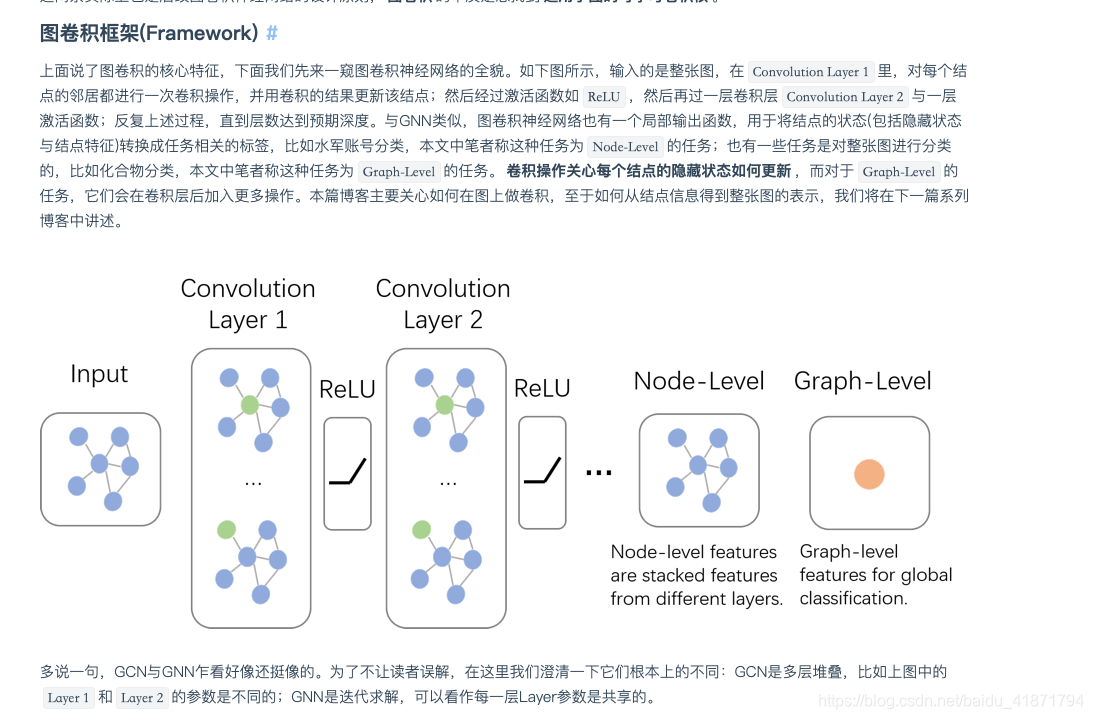
- 1.前言
- 2.图卷积网络的学习与理解
参考文章:https://zhuanlan.zhihu.com/p/54505069 https://zhuanlan.zhihu.com/p/89503068 https://www.cnblogs.com/SivilTaram/p/graph_neural_network_1.html
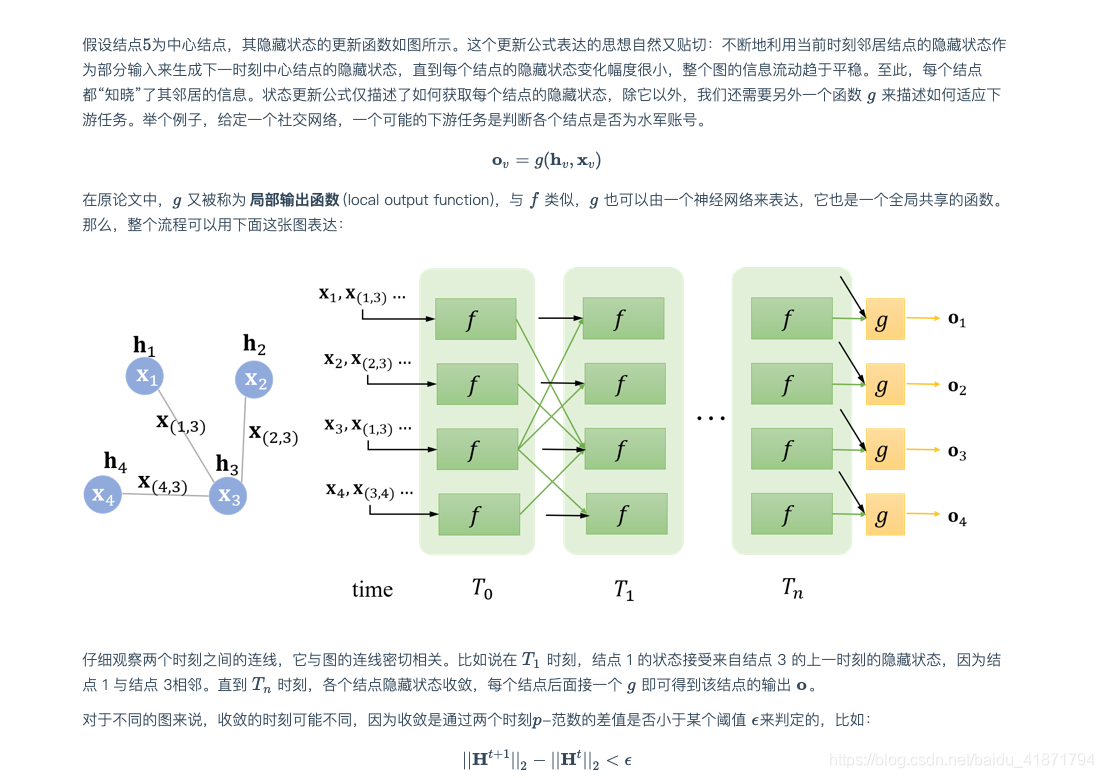
(1)图神经网络GNN
- 3.图卷积网络GCN的实现 (1)卷积层的定义
class GraphConvolution (nn.Module ): def __init__ (self, input_dim, output_dim, use_bias=True ): """图卷积:L*X*\theta Args: ---------- input_dim: int 节点输入特征的维度 D output_dim: int 输出特征维度 D‘ use_bias : bool, optional 是否使用偏置 """ super (GraphConvolution, self).__init__() self.input_dim = input_dim self.output_dim = output_dim self.use_bias = use_bias self.weight = nn.Parameter(torch.Tensor(input_dim, output_dim)) if self.use_bias: self.bias = nn.Parameter(torch.Tensor(output_dim)) else : self.register_parameter('bias' , None ) self.reset_parameters() def reset_parameters (self ): init.kaiming_uniform_(self.weight) if self.use_bias: init.zeros_(self.bias) def forward (self, adjacency, input_feature ): """邻接矩阵是稀疏矩阵,因此在计算时使用稀疏矩阵乘法 Args: ------- adjacency: 邻接矩阵 input_feature: torch.Tensor 输入特征 """ support = torch.mm(input_feature, self.weight) output = torch.mm(adjacency, support) if self.use_bias: output += self.bias return output
(2)GCN模型的定义
class GcnNet (nn.Module ): """ 定义一个包含两层GraphConvolution的模型 """ def __init__ (self, input_dim = 300 ,output_dim =300 ,dropout = 0.2 ): super (GcnNet, self).__init__() self.dropout = dropout self.gcn1 = GraphConvolution(input_dim, output_dim) self.gcn2 = GraphConvolution(input_dim, output_dim) self.linear = nn.Linear(input_dim,output_dim) """ S =ELU(A ̃ELU(A ̃XW +b )W +b ) """ def forward (self, adjacency, feature ): h = F.elu(self.gcn1(adjacency, feature)) s = F.dropout(h,p = self.dropout) s = self.gcn2(adjacency, h) output = self.linear(s) output = F.softmax(output) return output
- 1.前言