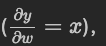介绍Pytorch中的自动微分系统(Autograd)
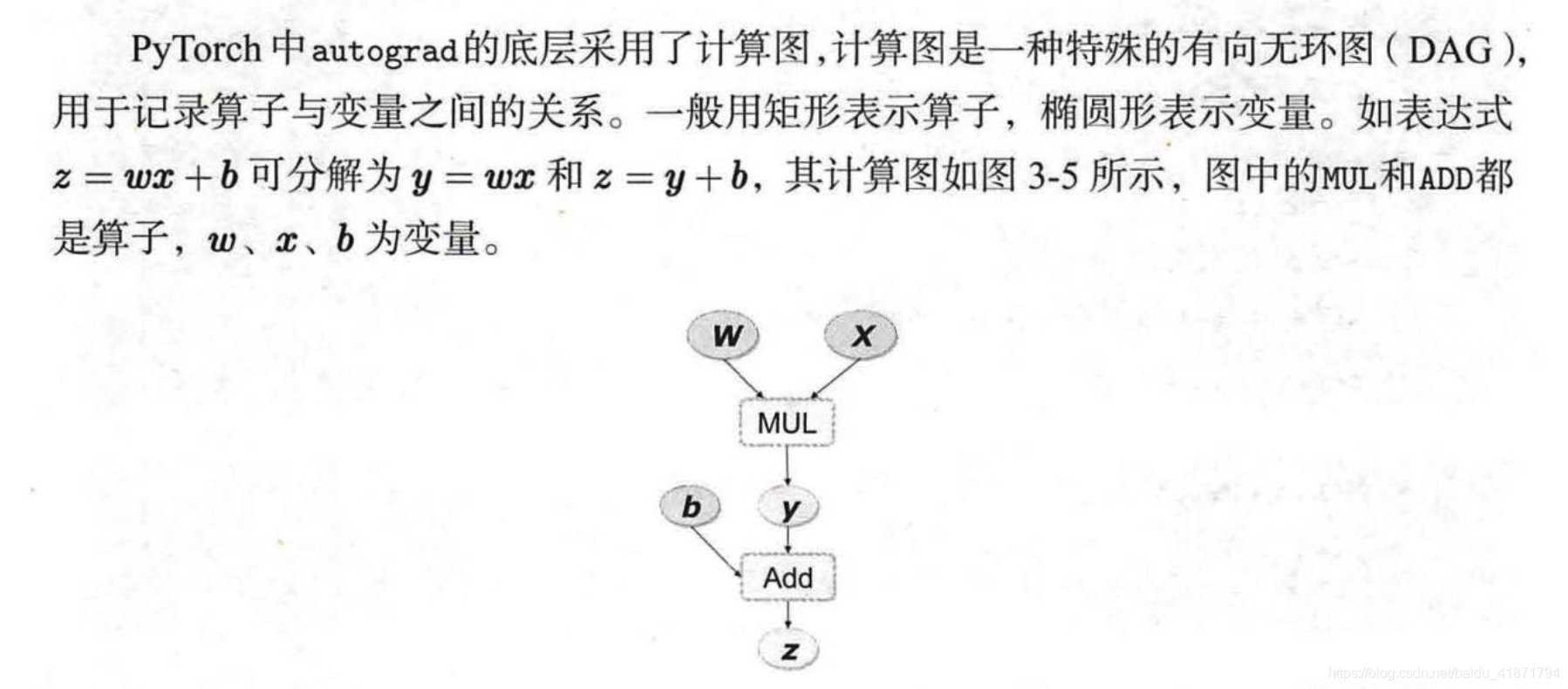
计算图(Computation Graph)是现代深度学习框架如PyTorch和TensorFlow等的核心,其为高效自动求导算法——反向传播(Back Propogation)提供了理论支持,了解计算图在实际写程序过程中会有极大的帮助。本节将涉及一些基础的计算图知识,但并不要求读者事先对此有深入的了解。
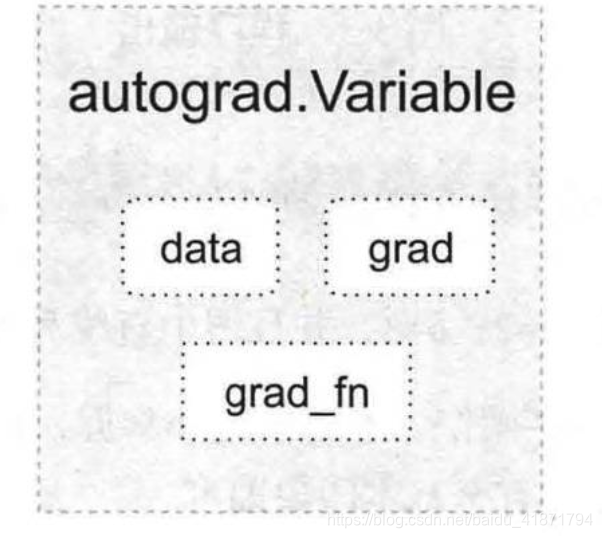
PyTorch在autograd模块中实现了计算图的相关功能,autograd中的核心数据结构是Variable。Variable封装了tensor,并记录对tensor的操作记录用来构建计算图。Variable的数据结构如图所示,主要包含三个属性:
data:保存variable所包含的tensorgrad:保存data对应的梯度,grad也是variable,而不是tensor,它与data形状一致。grad_fn: 指向一个Function,记录tensor的操作历史,即它是什么操作的输出,用来构建计算图。如果某一个变量是由用户创建,则它为叶子节点,对应的grad_fn等于None。
Variable的构造函数需要传入tensor,同时有两个可选参数:
requires_grad (bool):是否需要对该variable进行求导volatile (bool):意为”挥发“,设置为True,则构建在该variable之上的图都不会求导,专为推理阶段设计
Variable提供了大部分tensor支持的函数,但其不支持部分inplace函数,因这些函数会修改tensor自身,而在反向传播中,variable需要缓存原来的tensor来计算反向传播梯度。如果想要计算各个Variable的梯度,只需调用根节点variable的backward方法,autograd会自动沿着计算图反向传播,计算每一个叶子节点的梯度。
variable.backward(grad_variables=None, retain_graph=None, create_graph=None)主要有如下参数:
grad_variables:形状与variable一致,对于y.backward(),grad_variables相当于链式法则d z d x = d z d y × d y d x {dz \over dx}={dz \over dy} \times {dy \over dx} d x d z = d y d z × d x d y dz dy \textbf {dz} \over \textbf {dy} dy dz
retain_graph:反向传播需要缓存一些中间结果,反向传播之后,这些缓存就被清空,可通过指定这个参数不清空缓存,用来多次反向传播。
create_graph:对反向传播过程再次构建计算图,可通过backward of backward实现求高阶导数。
from __future__ import print_functionimport torch from torch.autograd import Variable
a = Variable(torch.ones(3 ,4 ), requires_grad = True ) b = Variable(torch.zeros(3 ,4 ))
c = a.add(b) d = c.sum () d.backward()
a.requires_grad, b.requires_grad, c.requires_grad
a.is_leaf, b.is_leaf, c.is_leaf
计算下面这个函数的导函数:
y = x 2 ∙ e x y = x^2\bullet e^x
y = x 2 ∙ e x
它的导函数是:
d y d x = 2 x ∙ e x + x 2 ∙ e x {dy \over dx} = 2x\bullet e^x + x^2 \bullet e^x
d x d y = 2 x ∙ e x + x 2 ∙ e x
来看看autograd的计算结果与手动求导计算结果的误差。
def f (x ): '''计算y''' y = x**2 * t.exp(x) return y def gradf (x ): '''手动求导函数''' dx = 2 *x*t.exp(x) + x**2 *t.exp(x) return dx
x = Variable(torch.randn(3 ,4 ), requires_grad = True ) y = f(x)
y.backward(torch.ones(y.size())) x.grad gradf(x)
在PyTorch实现中,autograd会随着用户的操作,记录生成当前variable的所有操作,并由此建立一个有向无环图。用户每进行一个操作,相应的计算图就会发生改变。更底层的实现中,图中记录了操作Function,每一个变量在图中的位置可通过其grad_fn属性在图中的位置推测得到。在反向传播过程中,autograd沿着这个图从当前变量(根节点z \textbf{z} z Backward结尾。下面结合代码学习autograd的实现细节。
x = Variable(torch.ones(1 )) b = Variable(torch.rand(1 ), requires_grad = True ) w = Variable(torch.rand(1 ), requires_grad = True ) y = w * x z = y + b
x.requires_grad, b.requires_grad, w.requires_grad y.requires_grad
计算w的梯度的时候,需要用到x的数值retain_graph来保留这些buffer。
z.backward(retain_graph=True ) w.grad
变量的requires_grad属性默认为False,如果某一个节点requires_grad被设置为True,那么所有依赖它的节点requires_grad都是True。volatile=True是另外一个很重要的标识,它能够将所有依赖于它的节点全部都设为volatile=True,其优先级比requires_grad=True高。volatile=True的节点不会求导,即使requires_grad=True,也无法进行反向传播。对于不需要反向传播的情景(如inference,即测试推理时),该参数可实现一定程度的速度提升,并节省约一半显存,因其不需要分配空间计算梯度。
x = Variable(torch.ones(1 )) w = Variable(torch.rand(1 ), requires_grad=True ) y = x * w x.requires_grad, w.requires_grad, y.requires_grad
在反向传播过程中非叶子节点的导数计算完之后即被清空。若想查看这些变量的梯度,有两种方法:
x = Variable(torch.ones(3 ), requires_grad=True ) w = Variable(torch.rand(3 ), requires_grad=True ) y = x * w z = y.sum () x.requires_grad, w.requires_grad, y.requires_grad
z.backward() (x.grad, w.grad, y.grad)
x = Variable(torch.ones(3 ), requires_grad=True ) w = Variable(torch.rand(3 ), requires_grad=True ) y = x * w z = y.sum () torch.autograd.grad(z, y)
def variable_hook (grad ): print('y的梯度: \r\n' ,grad) x = Variable(torch.ones(3 ), requires_grad=True ) w = Variable(torch.rand(3 ), requires_grad=True ) y = x * w hook_handle = y.register_hook(variable_hook) z = y.sum () z.backward() hook_handle.remove()
在PyTorch中计算图的特点可总结如下:
autograd根据用户对variable的操作构建其计算图。对变量的操作抽象为Function。
对于那些不是任何函数(Function)的输出,由用户创建的节点称为叶子节点,叶子节点的grad_fn为None。叶子节点中需要求导的variable,具有AccumulateGrad标识,因其梯度是累加的。
variable默认是不需要求导的,即requires_grad属性默认为False,如果某一个节点requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True。
variable的volatile属性默认为False,如果某一个variable的volatile属性被设为True,那么所有依赖它的节点volatile属性都为True。volatile属性为True的节点不会求导,volatile的优先级比requires_grad高。
多次反向传播时,梯度是累加的。反向传播的中间缓存会被清空,为进行多次反向传播需指定retain_graph=True来保存这些缓存。
非叶子节点的梯度计算完之后即被清空,可以使用autograd.grad或hook技术获取非叶子节点的值。
variable的grad与data形状一致,应避免直接修改variable.data,因为对data的直接操作无法利用autograd进行反向传播
反向传播函数backward的参数grad_variables可以看成链式求导的中间结果,如果是标量,可以省略,默认为1
PyTorch采用动态图设计,可以很方便地查看中间层的输出,动态的设计计算图结构。
import torch as tfrom torch.autograd import Variable as V%matplotlib inline from matplotlib import pyplot as pltfrom IPython import displayt.manual_seed(1000 ) def get_fake_data (batch_size=8 ): ''' 产生随机数据:y = x*2 + 3,加上了一些噪声''' x = t.rand(batch_size,1 ) * 20 y = x * 2 + (1 + t.randn(batch_size, 1 ))*3 return x, y x, y = get_fake_data() plt.scatter(x.squeeze().numpy(), y.squeeze().numpy()) w = V(t.rand(1 ,1 ), requires_grad=True ) b = V(t.zeros(1 ,1 ), requires_grad=True ) lr =0.001 for ii in range (8000 ): x, y = get_fake_data() x, y = V(x.float ()), V(y.float ()) y_pred = x.mm(w) + b.expand_as(y) loss = 0.5 * (y_pred - y) ** 2 loss = loss.sum () loss.backward() w.data.sub_(lr * w.grad.data) b.data.sub_(lr * b.grad.data) w.grad.data.zero_() b.grad.data.zero_() if ii%1000 ==0 : display.clear_output(wait=True ) x = t.arange(0 , 20 ).view(-1 , 1 ).float () y = x.mm(w.data) + b.data.expand_as(x) plt.plot(x.numpy(), y.numpy()) x2, y2 = get_fake_data(batch_size=20 ) plt.scatter(x2.numpy(), y2.numpy()) plt.xlim(0 ,20 ) plt.ylim(0 ,41 ) plt.show() plt.pause(0.5 ) print(w.data.squeeze()[0 ], b.data.squeeze()[0 ])