摘要
Urllib库是Python中的一个功能强大、用于操作URL,并在做爬虫的时候经常要用到的库。
urlopen方法
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
|
这是urllib.request.urlopen函数,第一个参数是网站的url,第二个参数是发送post请求时需要的数据,第三个参数是超时的设置(如果在规定的时间没有返回,则会报错),后面的三个参数暂时用不到,不过多叙述。
- 例子1:使用urlopen访问网页(get请求):
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(response.read().decode('utf-8'))
|
.read()方法会返回网页的源代码,这里需要使用utf-8进行解码。
- 例子2:使用urlopen访问网页(post请求):
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({'word':'hello'}), encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post',data=data)
print(response.read())
|
这里会输出一些json字符串,这个网址是用来做http测试的一个网址,它会返回一些请求测试数据。
http测试网址:http://httpbin.org
import urllib.request
import urllib.parse
response = urllib.request.urlopen('http://httpbin.org/get',timeout=1)
print(response.read())
|
如果没有超时,则会成功返回。如果超时,则程序报错。
响应
import urllib.request
import urllib.parse
response = urllib.request.urlopen('http://httpbin.org/get',timeout=1)
print(type(response))
|
这里使用type可以获取response的响应类型,结果如下。

- 获取状态码,响应头
这两个参数可以在浏览器的检查元素中network版块下找到,这里利用urllib的方法返回这两个参数。
import urllib.request
import urllib.parse
response = urllib.request.urlopen('http://httpbin.org/get',timeout=1)
print(response.status)
print(response.getheaders())
print(response.getheader('Server'))//这里会返回Server后面的参数
|
效果如下:

200表示连接成功
from urllib import request,parse
url = 'http://httpbin.org/post'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Host':'httpbin.org'
}
dict = {
'name':'Germey'
}
data = bytes(parse.urlencode(dict),encoding='utf8')
req = request.Request(url=url,data = data,headers=headers,method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
|
这个代码和第一个发送post请求的代码有所不同,但是返回结果相同,这里可以添加更多参数进行请求,在这里传入了base64编码后的from-data数据,headers,以及制定了method为post请求。
构造了request请求,返回结果为:
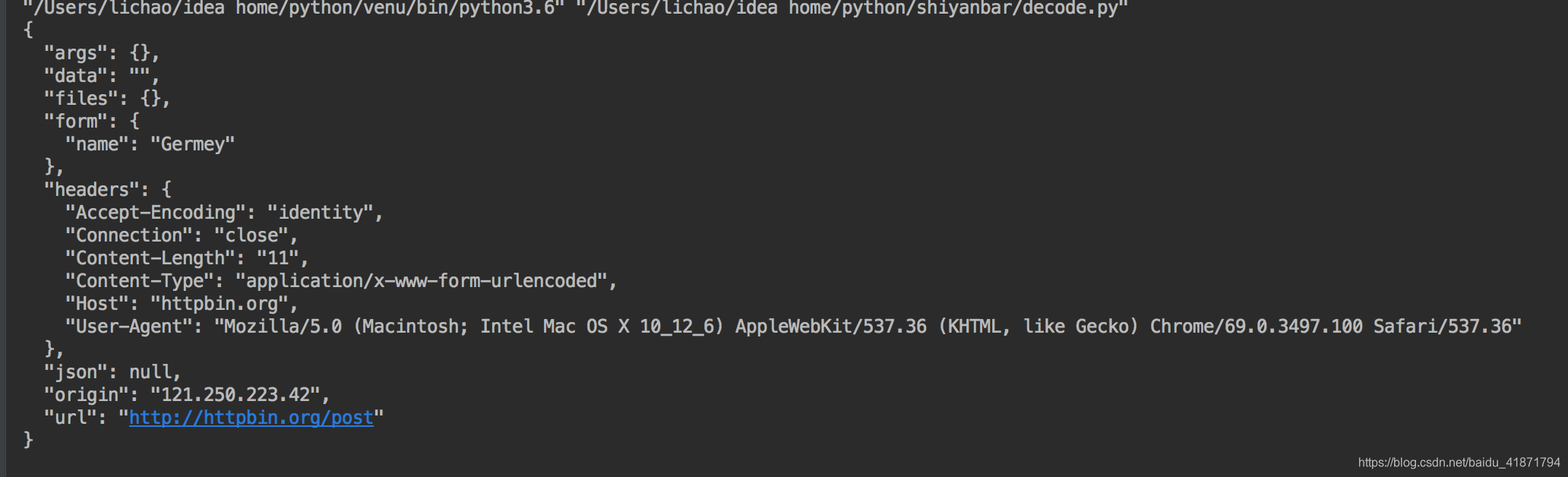
from urllib import request,parse
import urllib.request
proxy_handler = urllib.request.ProxyHandler({
'http':'http://127.0.0.1',
'https':'https://127.0.0.1'
})#里面的代理ip是你自己的代理的ip
opener = urllib.request.build_opener(proxy_handler)#加入代理,构造opener
response = opener.open('http://www.baidu.com')#请求网页
print(response.read())
|
- cookie
cookie是维持网页登陆状态需要用到的东西,里面储存了登陆信息,保存在本地,在写爬虫是,用cookie处理需要登陆的网页。
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()#将cookie声明为cookiejar的对象
hander = urllib.request.HTTPCookieProcessor(cookie)#借助header处理cookie
opener = urllib.request.build_opener(hander)#使用build_opener传入header
response = opener.open('http://www.baidu.com')#利用opener打开百度
for item in cookie:
print(item.name+"="+item.value)#cookie会被浏览器赋值,然后打印出来
|
具体分析在代码中,下面是执行结果:
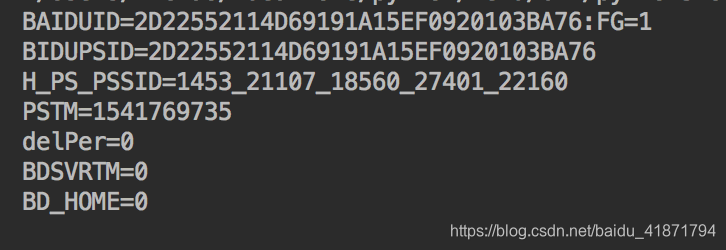
import http.cookiejar,urllib.request
filename = "cookie.txt"
cookie = http.cookiejar.MozillaCookieJar(filename)
hander = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(hander)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True,ignore_expires=True)
|
和刚才相似,只是将cookie保存到了本地,可以在cookie没有实效之前继续调用。
这里的cookie可以用不同的形式保存,只需要修改
cookie = http.cookiejar.MozillaCookieJar(filename)即可。
以上为本篇博客内容,下一次继续学习request库的使用






