TensorFlow 是一个面向深度学习算法的科学计算库,内部数据保存在张量(Tensor)对象 上,所有的运算操作(Operation,简称 OP)也都是基于张量对象进行的。这里介绍Tensorflow2.0的基础操作方法。
数据类型
TensorFlow 中的基本数据类型,包含数值类型、字符串类型和布尔类型。
数值类型
- 标量(Scalar) ,单个的实数,如 1.2, 3.4 等,维度(Dimension)数为 0,shape 为[]。;
a = 1.2
aa = tf.constant(1.2)
type(a), type(aa), tf.is_tensor(aa)
|
(float, tensorflow.python.framework.ops.EagerTensor, True)
|
- 向量(Vector) ,𝑛个实数的有序集合,通过中括号包裹,如[1.2],[1.2,3.4]等,维度数 为 1,长度不定,shape 为[𝑛];
a = tf.constant([1,2, 3.])
a, a.shape
|
(<tf.Tensor: shape=(3,), dtype=float32, numpy=array([1., 2., 3.], dtype=float32)>,
TensorShape([3]))
|
- 矩阵(Matrix) ,𝑛行𝑚列实数的有序集合,如[[1,2],[3,4]],维度数为 2,每个维度上的长度不定,shape 为[𝑛, 𝑚];
a = tf.constant([[1,2],[3,4]])
a, a.shape
|
(<tf.Tensor: shape=(2, 2), dtype=int32, numpy=
array([[1, 2],
[3, 4]], dtype=int32)>,
TensorShape([2, 2]))
|
- 张量(Tensor) ,所有维度数dim > 2的数组统称为张量。张量的每个维度也作轴(Axis);
tf.constant([[[1,2],[3,4]],[[5,6],[7,8]]])
|
<tf.Tensor: shape=(2, 2, 2), dtype=int32, numpy=
array([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]], dtype=int32)>
|
array([1. , 2. , 3.3], dtype=float32)
|
字符串类型
TensorFlow 还支持字符串(String) 类型的数据,例如在 表示图片数据时,可以先记录图片的路径字符串,再通过预处理函数根据路径读取图片张 量。通过传入字符串对象即可创建字符串类型的张量。
a = tf.constant('Hello, Deep Learning.')
a
tf.strings.lower(a)
|
<tf.Tensor: shape=(), dtype=string, numpy=b'Hello, Deep Learning.'>
<tf.Tensor: shape=(), dtype=string, numpy=b'hello, deep learning.'>
|
布尔类型
为了方便表达比较运算操作的结果,TensorFlow 还支持布尔类型(Boolean,简称 bool) 的张量。布尔类型的张量只需要传入 Python 语言的布尔类型数据,转换成 TensorFlow 内 部布尔型即可,例如:
tf.constant([True, False])
|
<tf.Tensor: shape=(2,), dtype=bool, numpy=array([ True, False])>
|
TensorFlow 的布尔类型和 Python 语言的布尔类型并不等价,不能通用
数值精度
常用的精度类型有 tf.int16、tf.int32、tf.int64、tf.float16、tf.float32、 tf.float64 等,其中 tf.float64 即为 tf.double。
创建张量时,可以指定张量保存的精度。
tf.constant(123456789, dtype=tf.int16)
tf.constant(123456789, dtype=tf.int32)
|
<tf.Tensor: shape=(), dtype=int16, numpy=-13035>
<tf.Tensor: shape=(), dtype=int32, numpy=123456789>
|
保存精度过低是,可能出现溢出。
类型转换
a = tf.constant(np.pi, dtype=tf.float16)
tf.cast(a, tf.double)
|
<tf.Tensor: id=44, shape=(), dtype=float64, numpy=3.140625>
|
a = tf.constant([True, False])
tf.cast(a, tf.int32)
|
<tf.Tensor: id=48, shape=(2,), dtype=int32, numpy=array([1, 0])>
|
待优化张量
tf.Variable 类型在普通的张量类型基础上添加了 name,trainable 等属性来支持计算图的构建。可以自动进行参数的梯度更新。
a = tf.constant([-1, 0, 1, 2])
aa = tf.Variable(a)
aa.name, aa.trainable
a = tf.Variable([[1,2],[3,4]])
|
('Variable:0', True)
<tf.Variable 'Variable:0' shape=(2, 2) dtype=int32, numpy=
array([[1, 2],
[3, 4]])>
|
创建 Variable 对象时是默认启用优化标志,可以设置 trainable=False 来设置张量不需要优化。
创建张量
从数组、列表对象创建
通过 tf.convert_to_tensor 函数可以创建新 Tensor,并将保存在 Python List 对象或者 Numpy Array 对象中的数据导入到新 Tensor 中。
tf.convert_to_tensor([1,2.])
tf.convert_to_tensor(np.array([[1,2.],[3,4]]))
|
<tf.Tensor: id=86, shape=(2,), dtype=float32, numpy=array([1., 2.],
dtype=float32)>
<tf.Tensor: id=88, shape=(2, 2), dtype=float64, numpy=
array([[1., 2.],
[3., 4.]])>
|
tf.constant()和 tf.convert_to_tensor()都可以自动将Numpy数组和列表转化为Tensor。
创建全0或全1张量
tf.zeros([]),tf.ones([])
tf.zeros([1]),tf.ones([1])
tf.zeros([2,2])
tf.ones([3,2])
|
tf.*_like 是一系列的便捷函数,创建相似的Tensor。
a = tf.zeros([3,2])
tf.ones_like(a)
|
<tf.Tensor: id=120, shape=(3, 2), dtype=float32, numpy=
array([[1., 1.],
[1., 1.],
[1., 1.]], dtype=float32)>
|
创建自定义数值张量
通过 tf.fill(shape, value)可以创建全为自定义数值 value 的张量,形状由 shape 参数指定。
tf.fill([], -1)
tf.fill([1], -1)
tf.fill([2,2], 99)
|
<tf.Tensor: id=128, shape=(1,), dtype=int32, numpy=array([-1])>
|
创建已知分布的张量
正态分布(Normal Distribution,或 Gaussian Distribution)和均匀分布(Uniform Distribution)是最常见的分布之一,创建采样自这 2 种分布的张量非常有用,比如在卷积神 经网络中,卷积核张量𝑾初始化为正态分布有利于网络的训练;在对抗生成网络中,隐藏变量𝒛一般采样自均匀分布。
- 通过 **tf.random.normal(shape, mean=0.0, stddev=1.0)**可以创建形状为 shape,均值为 mean,标准差为 stddev 的正态分布𝒩(mean, stddev2)。例如,创建均值为 0,标准差为 1 的正态分布:
tf.random.normal([2,2], mean=1,stddev=2)
|
<tf.Tensor: id=150, shape=(2, 2), dtype=float32, numpy=
array([[-2.2687864, -0.7248812],
[ 1.2752185, 2.8625617]], dtype=float32)>
|
- 通过 tf.random.uniform(shape, minval=0, maxval=None, dtype=tf.float32)可以创建采样自 [minval, maxval)区间的均匀分布的张量
tf.random.uniform([2,2],maxval=10)
|
创建序列
- 通过 tf.range(start, limit, delta=1)可以创建[start, limit),步长为 delta 的序列,不包含 limit 本身。
<tf.Tensor: id=190, shape=(5,), dtype=int32, numpy=array([1, 3, 5, 7, 9])>
|
张量的典型应用
标量
标量的一些典型用途是误差值的表示、各种测量指标的表示,比如准确度(Accuracy, 简称 acc),精度(Precision)和召回率(Recall)等
- 均方差误差函数tf.keras.losses.mse,返回每个样本上的误差值,最后取误差的均值作为当前 Batch 的误差,它是一个标量。
out = tf.random.uniform([4,10])
y = tf.constant([2,3,2,0])
y = tf.one_hot(y, depth=10)
loss = tf.keras.losses.mse(y, out)
loss = tf.reduce_mean(loss)
|
tf.Tensor(0.19950335, shape=(), dtype=float32)
|
向量
神经网络重的运算值。
fc = layers.Dense(3)
fc.build(input_shape=(2,4))
fc.bias
|
<tf.Variable 'bias:0' shape=(3,) dtype=float32, numpy=array([0., 0., 0.],
dtype=float32)>
|
矩阵
批量输入张量𝑿的形状为[𝑏, 𝑑in],其 中𝑏表示输入样本的个数,即 Batch Size,𝑑in表示输入特征的长度。
w = tf.ones([4,3])
b = tf.zeros([3])
|
<tf.Tensor: id=291, shape=(2, 3), dtype=float32, numpy=array([[ 2.3506963, 2.3506963, 2.3506963],
[-1.1724043, -1.1724043, -1.1724043]], dtype=float32)>
|
三维张量
典型应用是表示序列信号,它的格式是𝑿 = [𝑏, sequence len, feature len],其中𝑏表示序列信号的数量,sequence len 表示序列信号在时间维度上的采样点数或步数,feature len 表示每个点的特征长度。
x_train = keras.preprocessing.sequence.pad_sequences(x_train,maxlen=80)
x_train.shape
out = embedding(x_train)
out.shape
|
四维张量
保存特征图(Feature maps)数据,格式为[𝑏, h, w, 𝑐] ,代表图片数,高度,宽度,通道数。
索引与切片
通过索引与切片操作可以提取张量的部分数据
索引
TensorFlow 中,支持基本的[𝑖][𝑗] ⋯标准索引方式,也支持通过逗号分隔索引号的索引方式。
x = tf.random.normal([4,32,32,3])
x[0][1]
x[1,9,2]
|
切片
- 通过start: end: step切片方式可以方便地提取一段数据,其中 start 为开始读取位置的索 引,end
为结束读取位置的索引(不包含 end 位),step 为采样步长。

- step 可以为负数,当step = −1时,start: end: −1表 示从 start 开始,逆序读取至 end 结束(不包含 end),索引号𝑒𝑛𝑑 ≤ 𝑠𝑡𝑎𝑟𝑡。

维度变换
基本的维度变换操作函数包含了改变视图 reshape、插入新维度 expand_dims,删除维 度 squeeze、交换维度 transpose、复制数据 tile 等函数。
改变视图
可以更改数据的的表示方式。
通过 tf.reshape 视图改变函数产生不同的视图,可以将张量的视图任意地合法改变
在存储数据时,内存并不支持这个维度层级概念,只能以平铺方式按序写入内存,因此这 种层级关系需要人为管理,也就是说,每个张量的存储顺序需要人为跟踪。

其中-1代表着自动计算维度。
tf.reshape(x,[2,-1])
tf.reshape(x,[2,-1,3])
|
<tf.Tensor: id=520, shape=(2, 48), dtype=int32, numpy= array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14...80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95]])>
|
增、删维度
- 增加维度,通过 tf.expand_dims(x, axis)可在指定的 axis 轴前可以插入一个新的维度
x = tf.random.uniform([28,28],maxval=10,dtype=tf.int32)
x = tf.expand_dims(x,axis=2)
|
<tf.Tensor: id=13, shape=(28, 28, 1), dtype=int32, numpy= array([[[6],
[2],
[0],
[0],
[6],
[7],
[3],...
|
- 删除维度,通过 tf.squeeze(x, axis)函数,axis 参数为待删除的维度的索引号
x = tf.squeeze(x, axis=2)
|
<tf.Tensor: id=588, shape=(28, 28), dtype=int32, numpy=
array([[8, 2, 2, 0, 7, 0, 1, 4, 9, 1, 7, 4, 8, 2, 7, 4, 8, 2, 9, 8, 8, 0,
9, 9, 7, 5, 9, 7],
[3, 4, 9, 9, 0, 6, 5, 7, 1, 9, 9, 1, 2, 7, 2, 7, 5, 3, 3, 7, 2, 4,
5, 2, 7, 3, 8, 0],...
|
交换维度
- 使用 tf.transpose(x, perm)函数完成维度交换操作,参数 perm 表示新维度的顺序 List。
x = tf.random.normal([2,32,32,3])
tf.transpose(x,perm=[0,3,1,2])
|
<tf.Tensor: id=603, shape=(2, 3, 32, 32), dtype=float32, numpy= array([[[[-1.93072677e+00, -4.80163872e-01, -8.85614634e-01, ...,
1.49124235e-01, 1.16427064e+00, -1.47740364e+00], [-1.94761145e+00, 7.26879001e-01, -4.41877693e-01, ...
|
复制数据
- tf.tile(x, multiples)函数完成数据在指定维度上的复制操作,multiples 分别指 定了每个维度上面的复制倍数,对应位置为 1 表明不复制,为 2 表明新长度为原来长度的 2 倍,即数据复制一份,以此类推。
b = tf.constant([1,2])
b = tf.expand_dims(b, axis=0)
b
|
<tf.Tensor: id=645, shape=(1, 2), dtype=int32, numpy=array([[1, 2]])>
|
b = tf.tile(b, multiples=[2,1])
<tf.Tensor: id=648, shape=(2, 2), dtype=int32, numpy=array([[1, 2],[1, 2]])>
|
Broadcasting
Broadcasting 称为广播机制(或自动扩展机制),它是一种轻量级的张量复制手段,在逻 辑上扩展张量数据的形状,但是只会在需要时才会执行实际存储复制操作。对于大部分场 景,Broadcasting 机制都能通过优化手段避免实际复制数据而完成逻辑运算,从而相对于 tf.tile 函数,减少了大量计算代价。
数学运算
加、减、乘、除运算
- 通过 tf.add, tf.subtract, tf.multiply, tf.divide 函数实现,TensorFlow已经重载了+、 − 、 ∗ 、/运算符,一般推荐直接使用运算符来完成 加、减、乘、除运算。
- 整除和余除可以通过//和%运算符实现。
a = tf.range(5)
b = tf.constant(2) a//b
a%b
|
乘方运算
- 通过 tf.pow(x, a)可完成乘方运算,也可以通过运算符**实现x∗∗ 𝑎运算。
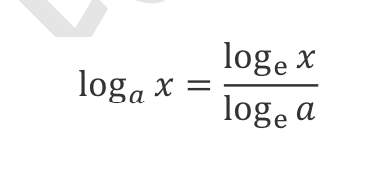
x = tf.constant([1.,2.])
x = 10**x
tf.math.log(x)/tf.math.log(10.)
|
矩阵相乘运算
- 通过@运算符可以方便的实现矩阵相乘,还可以通过 tf.matmul(a, b)函数实现。
a = tf.random.normal([4,28,32])
b = tf.random.normal([32,16])
tf.matmul(a,b)
|
上述运算自动将变量 b 扩展为公共 shape:[4,32,16],再与变量 a 进行批量形式地矩阵相 乘,得到结果的 shape 为[4,28,16]。
向前传播实例
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow.keras.datasets as datasets
plt.rcParams['font.size'] = 16
plt.rcParams['font.family'] = ['STKaiti']
plt.rcParams['axes.unicode_minus'] = False
def load_data():
(x, y), (x_val, y_val) = datasets.mnist.load_data()
x = tf.convert_to_tensor(x, dtype=tf.float32) / 255.
y = tf.convert_to_tensor(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
x = tf.reshape(x, (-1, 28 * 28))
train_dataset = tf.data.Dataset.from_tensor_slices((x, y))
train_dataset = train_dataset.batch(200)
return train_dataset
def init_paramaters():
w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1))
b1 = tf.Variable(tf.zeros([256]))
w2 = tf.Variable(tf.random.truncated_normal([256, 128], stddev=0.1))
b2 = tf.Variable(tf.zeros([128]))
w3 = tf.Variable(tf.random.truncated_normal([128, 10], stddev=0.1))
b3 = tf.Variable(tf.zeros([10]))
return w1, b1, w2, b2, w3, b3
def train_epoch(epoch, train_dataset, w1, b1, w2, b2, w3, b3, lr=0.001):
for step, (x, y) in enumerate(train_dataset):
with tf.GradientTape() as tape:
h1 = x @ w1 + tf.broadcast_to(b1, (x.shape[0], 256))
h1 = tf.nn.relu(h1)
h2 = h1 @ w2 + b2
h2 = tf.nn.relu(h2)
out = h2 @ w3 + b3
loss = tf.square(y - out)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
w3.assign_sub(lr * grads[4])
b3.assign_sub(lr * grads[5])
return loss.numpy()
def train(epochs):
losses = []
train_dataset = load_data()
w1, b1, w2, b2, w3, b3 = init_paramaters()
for epoch in range(epochs):
loss = train_epoch(epoch, train_dataset, w1, b1, w2, b2, w3, b3, lr=0.001)
print('epoch:', epoch, 'loss:', loss)
losses.append(loss)
x = [i for i in range(0, epochs)]
plt.plot(x, losses, color='blue', marker='s', label='训练')
plt.xlabel('Epoch')
plt.ylabel('MSE')
plt.legend()
plt.show
train(epochs=20)
|










