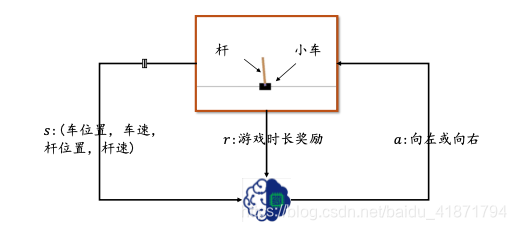
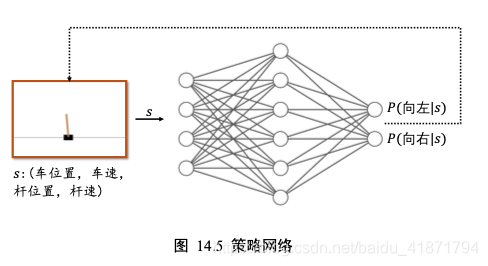
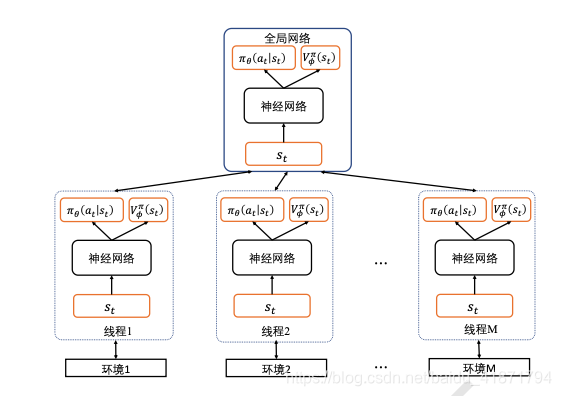
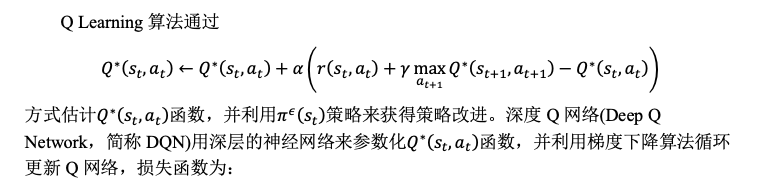import collections
import random
import gym,os
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers,optimizers,losses
env = gym.make('CartPole-v1')
env.seed(1234)
tf.random.set_seed(1234)
np.random.seed(1234)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
learning_rate = 0.0002
gamma = 0.99
buffer_limit = 50000
batch_size = 32
class ReplayBuffer():
def __init__(self):
self.buffer = collections.deque(maxlen=buffer_limit)
def put(self, transition):
self.buffer.append(transition)
def sample(self, n):
mini_batch = random.sample(self.buffer, n)
s_lst, a_lst, r_lst, s_prime_lst, done_mask_lst = [], [], [], [], []
for transition in mini_batch:
s, a, r, s_prime, done_mask = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
done_mask_lst.append([done_mask])
return tf.constant(s_lst, dtype=tf.float32),\
tf.constant(a_lst, dtype=tf.int32), \
tf.constant(r_lst, dtype=tf.float32), \
tf.constant(s_prime_lst, dtype=tf.float32), \
tf.constant(done_mask_lst, dtype=tf.float32)
def size(self):
return len(self.buffer)
class Qnet(keras.Model):
def __init__(self):
super(Qnet, self).__init__()
self.fc1 = layers.Dense(256, kernel_initializer='he_normal')
self.fc2 = layers.Dense(256, kernel_initializer='he_normal')
self.fc3 = layers.Dense(2, kernel_initializer='he_normal')
def call(self, x, training=None):
x = tf.nn.relu(self.fc1(x))
x = tf.nn.relu(self.fc2(x))
x = self.fc3(x)
return x
def sample_action(self, s, epsilon):
s = tf.constant(s, dtype=tf.float32)
s = tf.expand_dims(s, axis=0)
out = self(s)[0]
coin = random.random()
if coin < epsilon:
return random.randint(0, 1)
else:
return int(tf.argmax(out))
def train(q, q_target, memory, optimizer):
huber = losses.Huber()
for i in range(10):
s, a, r, s_prime, done_mask = memory.sample(batch_size)
with tf.GradientTape() as tape:
q_out = q(s)
indices = tf.expand_dims(tf.range(a.shape[0]), axis=1)
indices = tf.concat([indices, a], axis=1)
q_a = tf.gather_nd(q_out, indices)
q_a = tf.expand_dims(q_a, axis=1)
max_q_prime = tf.reduce_max(q_target(s_prime),axis=1,keepdims=True)
target = r + gamma * max_q_prime * done_mask
loss = huber(q_a, target)
grads = tape.gradient(loss, q.trainable_variables)
optimizer.apply_gradients(zip(grads, q.trainable_variables))
def main():
env = gym.make('CartPole-v1')
q = Qnet()
q_target = Qnet()
q.build(input_shape=(2,4))
q_target.build(input_shape=(2,4))
for src, dest in zip(q.variables, q_target.variables):
dest.assign(src)
memory = ReplayBuffer()
print_interval = 20
score = 0.0
optimizer = optimizers.Adam(lr=learning_rate)
for n_epi in range(10000):
epsilon = max(0.01, 0.08 - 0.01 * (n_epi / 200))
s = env.reset()
for t in range(600):
a = q.sample_action(s, epsilon)
s_prime, r, done, info = env.step(a)
done_mask = 0.0 if done else 1.0
memory.put((s, a, r / 100.0, s_prime, done_mask))
s = s_prime
score += r
if done:
break
if memory.size() > 2000:
train(q, q_target, memory, optimizer)
if n_epi % print_interval == 0 and n_epi != 0:
for src, dest in zip(q.variables, q_target.variables):
dest.assign(src)
print("# of episode :{}, avg score : {:.1f}, buffer size : {}, " \
"epsilon : {:.1f}%" \
.format(n_epi, score / print_interval, memory.size(), epsilon * 100))
score = 0.0
env.close()
if __name__ == '__main__':
main()
|